ELEC 5650 - Kalman Filter
"We have decided to call the entire field of control and communication theory, whether in the machine or in the animal, by the name Cybernetics, which we form from the Greek ... for steersman."
-- by Norbert Wiener
This is the lecture notes for "ELEC 5650: Networked Sensing, Estimation and Control" in the 2024-25 Spring semester, delivered by Prof. Ling Shi at HKUST. In this session, we will deviate Kalman Filter from three different perspectives: Geometric, Probabilistic, and Optimization approaches. Each perspective provides unique insights into understanding and implementing the Kalman Filter algorithm.


Takeaway Notes
Consider an LTI system with initial conditions
Find the estimation of
Assumptions
is controllable and is observable , and are mutually uncorelated - The future state of the system is conditionally independent of the past states given the current state
Time Update
Measurement Update
Geometric Perspective (LMMSE Estimation)
The Geometric perspective views Kalman Filter as a Linear Minimum Mean Square Error (LMMSE) estimator, which is rooted in orthogonal projection theory in Hilbert space. The key insight is that the Kalman Filter's innovation term

Time Update
Measurement Update
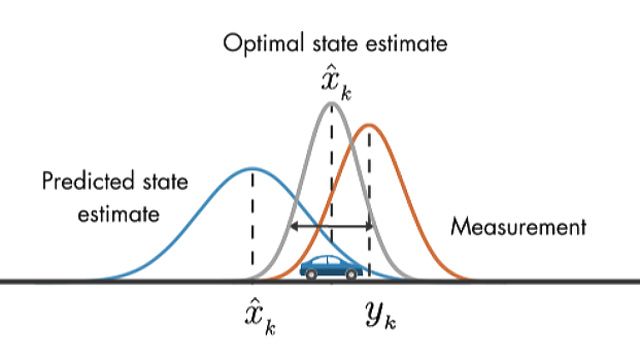
Probabilistic Perspective (Bayesian Estimation)
The filter maintains a Gaussian belief state that gets refined through sequential application of Bayes' rule, where prediction corresponds to Chapman-Kolmogorov propagation and update implements Bayesian conditioning.
Applying Bayesian Rule and Markov Assumptions to
Optimization Perspective (MAP Estimation)
The Kalman Filter solves a weighted least-squares problem where the optimal state estimate minimizes a cost function balancing prediction fidelity against measurement consistency, with covariance matrices acting as natural weighting matrices.
By Bayesian Rule, we know that
To maximize the posterior probability, it is equivalent to minimizing its negative logarithmic posterior.
Applying Gaussian probability distribution
Prior is given by